
I shipped a diary skill for Claude Code recently. Hooks capture raw events; the model synthesizes them into first-person prose at the end of each session. It has worked well as a rear-view mirror. Months from now, when a future agent picks up the project, the events log and the synthesized entries together are enough to reconstruct what happened and why.
But the diary can't tell you anything about the future. Open the project on a Saturday afternoon with two Claude Codeinstances running in separate git worktrees and you immediately face questions the diary can't answer. What's left to do? Which piece is the other instance already on? When I come back tomorrow, where do I pick up? A diary describes the past tense; a project needs a present and a future tense as well.
The standard solution to that is a tracker. And four weeks ago, OpenAI shipped Symphony — an open-source spec that turns exactly this kind of state into a coordination protocol. Symphony treats an issue tracker as a state machine: each ticket gets its own agent and its own workspace; tickets move through Todo / In Progress / Review / Merging; agents that crash or stall mid-task are respawned automatically. OpenAI reported a sixfold jump in merged pull requests on internal teams during Symphony's first three weeks. An outside fork ports the spec to Claude Code with GitHub Issues as the tracker.
The shape is right. The weight is wrong, at least for me.
What "the weight is wrong" means
Symphony assumes Linear or GitHub Issues as the control plane. It assumes a coordinator process polling that tracker. It assumes agents working mostly autonomously between human checkpoints, with the human reviewing merge candidates rather than managing sessions. That is a real architecture for a real-shape problem — a team of engineers wanting to put their issue tracker on autopilot. It is not the shape of my problem.
My problem looks like this. I have two terminals open on a Saturday. One is running Claude Code in the feature/paymentworktree, the other in feature/auth-refactor. I want both of them to be able to see what else is planned for this project, to claim a piece of work without me dispatching it, and to mark it done when they finish. I want to be able to glance at some artifact and see who is working on what, without logging into Linear, without standing up a coordinator process, without committing my project to Symphony's spec for the rest of its life.
In other words I want a board — but I want the board to be a file in the repo, not a service somewhere else.
This is where Thariq Shihipar's now-famous line "HTML is the new markdown" becomes important. The argument, very briefly: markdown is fine as a config format — CLAUDE.md, SKILL.md, the rest — but it is poor as an output format that humans are supposed to engage with. A thousand-line markdown plan becomes a wall of text. An HTML artifact, visual and scrollable and sometimes interactive, is something you actually read. A board of cards is exactly the shape that markdown loses badly to HTML. A markdown checklist is a wall of text; a kanban board with columns and chips and color-coded priority is something the eye can take in at a glance.
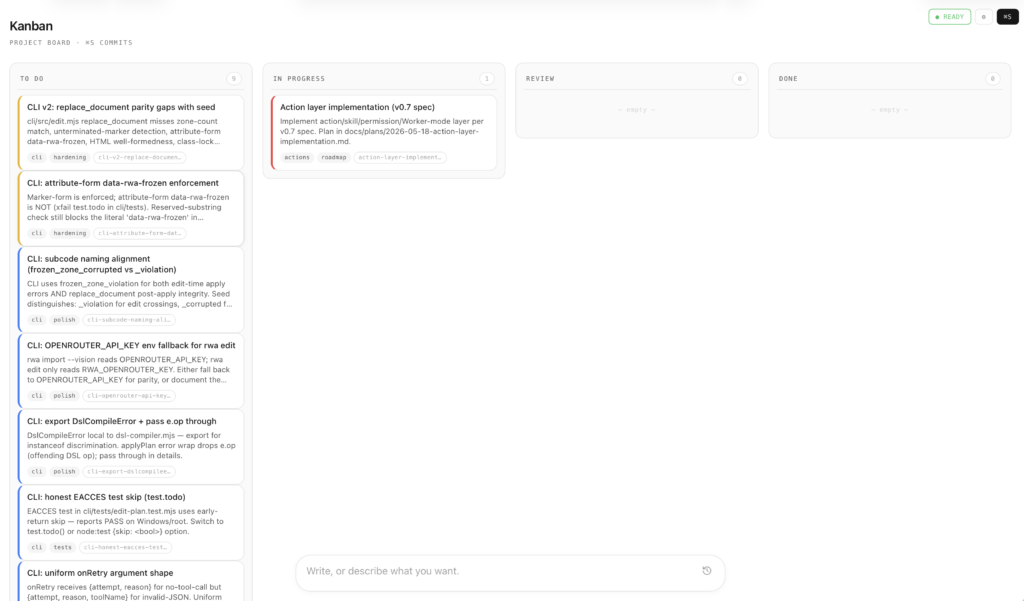
So the board should be HTML, not markdown. Good. Now where does the HTML live?
The substrate
I have been working with rewritable for a few months. It is a small spec that defines what a "self-rewriting HTML container" looks like: one .html file that includes its own runtime, its own data, and the ability to commit changes back to the file on disk via the File System Access API. Open it in Chrome, edit it, press ⌘S, and the file on disk is updated in place. Close the tab, reopen it, the state is still there because it is the file. No backend, no database, no server. Just an HTML file that is also an application.
For a project kanban this is the right substrate at the right level. .kanban/board.html becomes the board. It is a file you can cat, grep, git add, email to yourself, or open in any modern browser. The kanban app is part of the file; opening it in Chrome gives you the visual board with drag-and-drop. There is no separate viewer to install, no tracker service to sign into, and no orchestrator process to start. The board is the artifact, in the same way the diary's entries are the artifact for retrospective state.
This is also where the architecture pays for itself a second time. The diary skill and the kanban skill have nothing to do with each other technically — different files, different storage, different invocation patterns — but they sit on the same conceptual axis. The diary captures the past; the kanban describes the present and the immediate future. Both live as files in the project; both can be read and written by Claude; both can be opened by a human without any tooling. Symphony solves a similar problem at a much higher level of abstraction. This is the same problem at the lowest level of abstraction I could find.
Two surfaces, one file
The kanban skill ships a small Bash CLI surface for Claude — init, add, claim, move, note, list — that edits the cards array atomically. A typical session reads like this:
$ kanban add "Refactor auth to use middleware pattern" --priority=high --tags=auth,refactor
2026-05-20-refactor-auth-to-use-middleware-pattern
$ kanban claim 2026-05-20-refactor-auth-to-use-middleware-pattern
claimed 2026-05-20-refactor-auth-to-use-middleware-pattern by alpha
$ kanban list
TO DO (1)
2026-05-20-investigate-flaky-test Investigate flaky test
IN PROGRESS (1)
! 2026-05-20-refactor-auth-to-use-middleware-pattern Refactor auth to use middleware pattern [alpha] #auth #refactor
REVIEW (1)
· 2026-05-20-document-the-api-endpoints Document the API endpoints #docs
The four columns — To Do, In Progress, Review, Done — match Symphony's state machine almost exactly, minus the auto-merge step. Each card is a JSON object inside a <script type="application/json" id="kanban-cards"> block in the HTML file. The Bash scripts compose into a Python helper, rwa_splice.py, that edits the JSON region in place via os.replace, never parsing any HTML. The browser-side inline runtime reads the same JSON on page load, renders the columns and binds drag-and-drop, and writes mutations back into the JSON block before the rwa runtime commits the file on ⌘S.
The most interesting piece is what assignee identity does. The skill reads $KANBAN_AGENT_NAME if it is set — alpha, beta, review, whatever feels right per worktree — and otherwise falls back to a short hash of $CLAUDE_SESSION_ID. Set KANBAN_AGENT_NAME=alpha in one terminal's shell and KANBAN_AGENT_NAME=beta in another, and the cards each instance claims show their owner as a dark chip. A claim attempt against an already-claimed card exits 2 instead of taking it over. Agents notice each other rather than collide.
That is the entire coordination story. No messaging system. No supervisor. No central agent. Two Claude Code sessions, two shell environments, one file. The claim → exit 2 protocol is the whole delegation primitive, and it turns out to be exactly enough for one person running parallel sessions.
What the first version got wrong
The first cut had a quietly bad bug, and it taught me something I should have remembered from working on rewritable in the first place.
The rwa runtime hydrates the document from IndexedDB on every page load, ignoring the INLINE_DOC literal in the file once IDB has been populated. This is normally what you want — IDB is the working state, and reloads should not roll back uncommitted edits. But for a kanban board it meant that anything Claude wrote to the file from the CLI was invisible to an open browser tab. The user would press F5 and nothing would change. Telling them to "clear IndexedDB and reload" worked, but it was the wrong default. I had shipped a board that quietly lied about its own state, and tucked the workaround into the reference docs as if it were a feature.
The fix turned out to be smaller than the bug. The kanban runtime — the inline JS inside INLINE_DOC — now polls fetch(location.href) every 2.5 seconds while the tab is visible. It parses the cards JSON out of the literal in the response, three-way-merges against the previous poll's disk state and the cards currently in the DOM, and writes the merged result back. CLI-side additions, claims, moves, notes, and deletes appear in open tabs automatically, with new cards getting a brief highlight pulse. Local drags that have not been committed yet survive the merge: if the human dragged card-X to a new column and the CLI later updated card-Y, both changes stick. The only ambiguous case — a drag and a CLI write both touching the same card — resolves to the drag, because the human just acted, and reverting them would be more confusing than the alternative.
The loop is self-quiescing. When the disk state equals the DOM state, the poll completes in a few milliseconds and nothing visible happens. When something has changed, the diff propagates. There is no banner, no modal, no clear-the-cache instruction. The board just stays in sync.
The lesson was a small one but the kind I keep relearning: documenting a workaround is not the same as fixing the bug. The first instinct, when something does not work, is to add a sentence to the README. The right instinct is to ask whether the system could close the loop itself, and ship it when it can.
What the board is actually for
Two purposes, restated concretely now that the mechanics are out of the way.
The first is human-readable status. When I sit down on a Saturday morning, I can open .kanban/board.html in Chrome and see what is outstanding without reading anyone's prose. The Refactor card has a red left border because it is high priority. The Documentation card is in Review with no assignee, which tells me my last session finished it and I have not looked yet. The investigation card sits in To Do with no tags. That is the entire state of the project, taken in at a glance, in the time it takes to drink half a coffee.
The second is coordination between parallel sessions. When I start one Claude Code instance and tell it "pick something off the board," it runs kanban list --status=todo, picks the highest-priority unclaimed card, claims it, and starts. If a second instance does the same a minute later, the second claim exits 2 against the first card and the agent picks the next one down. No one had to dispatch. No coordinator had to route. The board was the only state anyone needed.
There is a third thing the board does that I did not plan for, which is the most useful in practice. When the diary skill produces its end-of-session entry, the entries reference cards by id — pivoted on 2026-05-20-refactor-auth after the express middleware approach broke on async error handling. The card id is a stable, copy-pasteable handle that survives across sessions, across worktrees, across agents. Diary and kanban share no code, but they share a vocabulary, and the project gains a continuity that no single tool would have given it.
The lightweight version exists because the right size of a tool depends on the size of the operation. Symphony is the right shape for a team of engineers wanting their issue tracker on autopilot. For one developer with two Claude Code sessions and a substrate that already self-rewrites, the answer is .kanban/board.html — a file you can drag, open without permission, and read at a glance.
Shipping it
The kanban skill is on GitHub at ikangai/claude-skills. Install into Claude Code with:
mkdir -p ~/.claude/skills && unzip -o kanban.zip -d ~/.claude/skills/
Restart Claude Code so the skill is picked up, then run kanban init in any project root to create .kanban/board.html. The first card you add will be the first entry on a board that will, with luck, eventually accumulate the texture of a project the way the diary accumulates the texture of a session.